This article was originally published at hackernoon.
What makes Kafka so Fast? A Deep Dive into Kafka Storage Internals.
At most tech companies, we are constantly exposed to a variety of challenging problems, within the real-time streaming realm, and hence we make use of a distributed system like Kafka very heavily. I feel highly encouraged to have a solid understanding of the internals of such systems, especially when we plan to use them in production, so to be able to define the use-case well with such tools, and be able to debug issues, or make decisions like: when to use what!
My aim with this series of blogs is to be able to comprehensively explain the fundamental details of how Kafka was designed. There are various documents and other really good resources that are available out there, but the purpose of this series is to be more elaborative with visual representations, and more comprehensive than the rest, so that the beginners who want to learn about such Distributed Systems have all the resources and prerequisite fundamental knowledge under one roof, which sometimes, in my opinion, is just referenced in original docs. Hence, with this series, I wish to avoid most of the resource branching, and make it more beginner-friendly to work with!
Fundamental Pre-requisites
Before diving deep into the Kafka Storage architecture, let’s discuss some important aspects of disk access patterns.
Question: Are disks really slow?
Answer: It highly depends on how we access data. For around a decade, it has been observed that the throughput i.e. the linear reads and writes of disks have been increasing, and these operations are being highly optimised by Operating Systems when comparing them to disk seek.
In the case of the linear reads and writes, the access pattern becomes very predictable. For example, for the specific case of reading, the OS can use certain techniques like read-ahead that can prefetch a larger amount of data at once, hence increasing the performance on reads.
Some research has found that sequential disk access in some cases can be faster than random memory access! [ 1 ]
![Source: The Pathologies of Big Data, ACM Queue Article [1]](https://dl.acm.org/cms/attachment/d7e5eb0f-c89d-401e-84bb-c85042b4c072/jacobs3.jpg)
Image Source: The Pathologies of Big Data, ACM Queue Article [1]
Question: What is a PageCache? How is it different from In-Process Caching?
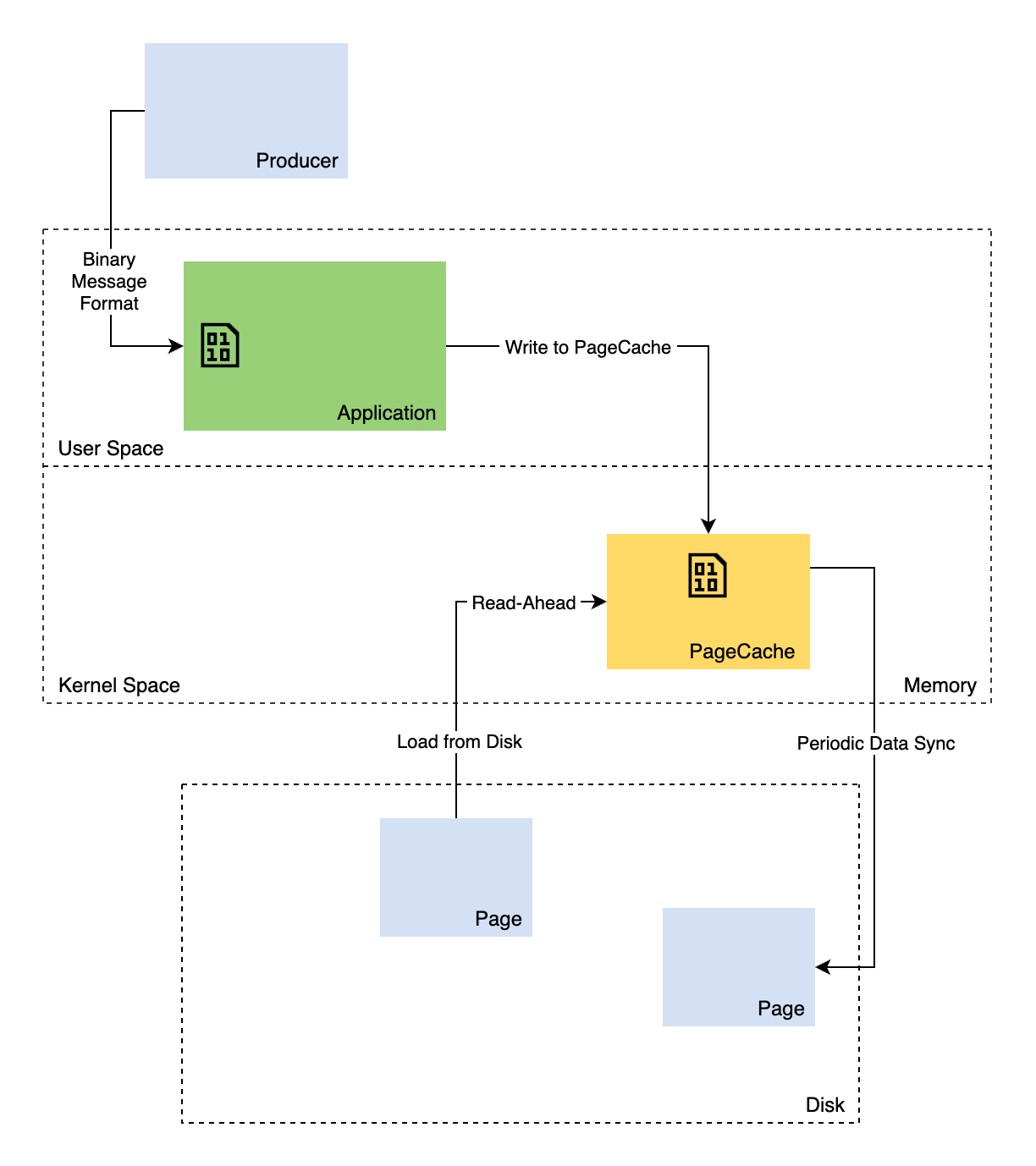
Answer: PageCache is a cache created of a page from a storage device like a disk. It is managed by the Operating System, implemented in kernels, and is kept in the unused portions of the main memory i.e in the RAM.
This helps in quickly accessing the contents of the page, as it is now stored in memory. PageCache is transparent to all the applications being run and is not bound to any application process. Hence, even if an application crashes, the PageCache still remains and can be used again. The operating system might also mark this as free or available memory. Whenever the system requires more memory the PageCache can be discarded or flushed to disk (if modified) and the memory can be made available to the Operating System.
There’s also a different kind of cache called the in-process cache, which is primarily controlled by the application process. Unlike PageCache, whenever the application crashes or restarts, the in-process cache is also discarded and needs to be recreated while booting up the application, hence might take more time to make the cache warm.
How Kafka does it?
Kafka heavily relies on the file system and uses a lot of storage and caching-related aspects discussed above. The developers of Kafka find that using a PageCache over an in-process cache would be much more efficient when amortised over time and under high load.
It doesn’t wait for the data to actually persist to disk, leaving it to the OS to take care for, and just sends out ack once it writes to the PageCache, thus making it more performant.
So, for a system that heavily relies on writing and reading data from a disk, using an in-process cache would cause duplication of data as this data would also be written in a PageCache, hence storing everything twice. Also, since the access to data inside Kafka is sequential and not random, it’s easier for the OS to fetch and load pages from disk to PageCache using read-ahead techniques.
Kafka is mostly written in Java, and only with languages based on JVM.
Question: What are some things to keep in mind for applications that are based on JVM?
Answer: Whenever we plan to store something in memory through objects in JVM, the memory for storing them becomes almost twice or even more. Which could be mostly due to some extra bytes of housekeeping information, some bytes of the actual fields and reference to other objects, and some more extra space because JVM and/or the processor architecture will typically require object data to be padded to some specific number of bytes.
Also, as the in-heap data grows, java’s garbage collection can become increasingly slow.
To summarise, the following points helped Kafka Developers to make the decision for using a PageCache than an In-Process cache:
-
Automatic access to all the freely available memory
-
Double the size of a JVM based in-process cache
-
Cache stays warm even if the Kafka process crashes
-
The process of reading and writing from the cache to disk is delegated to the operating system, hence simplifying the implementation to move data to and from the Cache and Disk
-
If your disk usage favours linear reads then read-ahead is effectively pre-populating this cache with useful data on each disk read.
Hence, this makes the design very simple by just reading and writing directly to PageCache, and not needing to flush everything every time to disk, which is efficiently handled by the operating system.
Question: So, how Reliable and Durable is the Data Stored inside Kafka?
The astute reader might argue about the reliability and durability of data that is written to a PageCache which belongs to the kernel space of the main memory, as compared to writing to a persistent storage device like a disk.
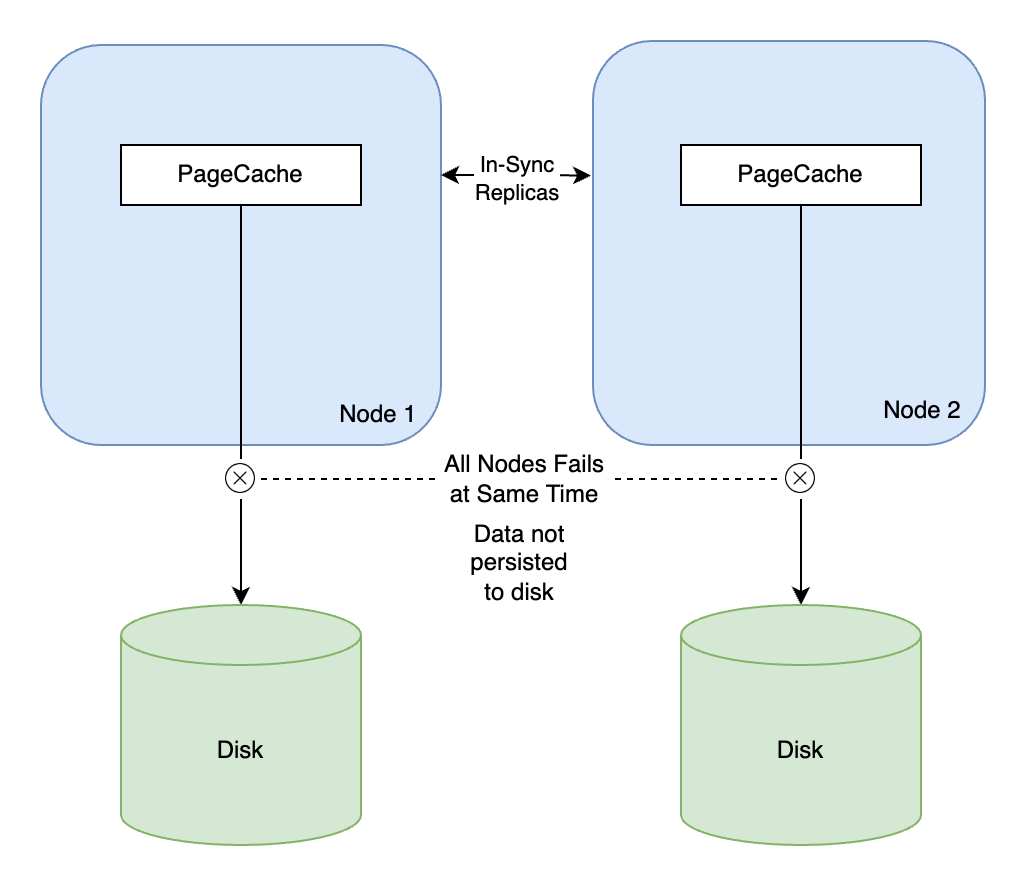
Reliability & Durability of Data Stored in Kafka
Answer: If the node on which Kafka runs crashes (assuming a single-node Kafka cluster), there is a big possibility of data loss. As flushing to disk is handled by operating system, the un-flushed PageCache data would be lost on node crash as it resides on memory. To make Kafka more fault-tolerant it is generally advised to have enough replicas of topics stored in Kafka, running on different nodes, with Rack-Awareness which can make it very less probable to lose data.
With that, it is important to configure a reasonable replication factor and in-sync replica values.
Unlikely though, data loss can still occur if all the nodes on which the replicas run, go down, simultaneously.
Kafka developers encourage using Kafka with enough replication to avoid such a scenario, hence making data loss less likely.
What Next?
We saw how Kafka makes the file system look really cool; while keeping the caches warm!
This would be all for the Storage and Persistence section in the Kafka Design. Please feel free to comment below and ask me anything related to what we discussed above.
Further, in the next part, we would dive deeper into the data transfer and networking aspects and how it is efficiently done in Kafka!