This article was originally published at Koverhoop Medium Publication.
Moving from Batch to Event-Based Real-time Systems
In a lot of technical scenarios, and, at Koverhoop, we face the need to move data from the sources of truth to other downstream destination data stores.
Some use-cases really demand a system that requires data to be available in real-time (or near real-time) latencies.
These could be:
- Moving relational data from a database like Postgres to a search index like Elasticsearch.
- Joining or aggregating incoming streams of data to create a Materialized Cache that keeps updating in near real-time.
- Implementing an ETL or ELT for a Data Warehouse by streaming data from all your micro-services.
- Or setting up a Primary-Replica infrastructure for load-balancing.
- Using it as a near-real time cache-invalidation and updation pipeline (similar to #2).
See my other post for doing #1 and #2
For #4, watch out for my upcoming blog on setting up and managing a Postgres Primary-Replica infrastructure
Building such pipelines has always been a tricky affair, and more so if it needs to be done in a real-time fashion.
In this post, I’ll get hands-on implementing a real-time data extraction approach to extract data from a database system like Postgres, efficiently. I’ll also refer you to a Github Repository where you can have this set up in no time (familiarity with Docker is expected).
Possible Solutions to Extracting Data
Batch-based SQL Queries
The most basic data extraction approach used in most traditional ETL or ELT systems is making periodic SQL queries on required tables and load them into warehouses.
Queries can be made more efficient by doing incremental updates by keeping a record of the last committed timestamp than to snapshot the entire database repeatedly
Note: Doing this would require having a timestamp column on every table that updates its value for a row whenever it is changed.
Pros:
- Easy to Implement
- Easier to deal with, if denormalization is to be applied
Cons:
- Can have an adverse impact on database performance due to periodic queries.
- Data freshness can vary from hours, to days, to weeks.
Logs-based Data Capturing.
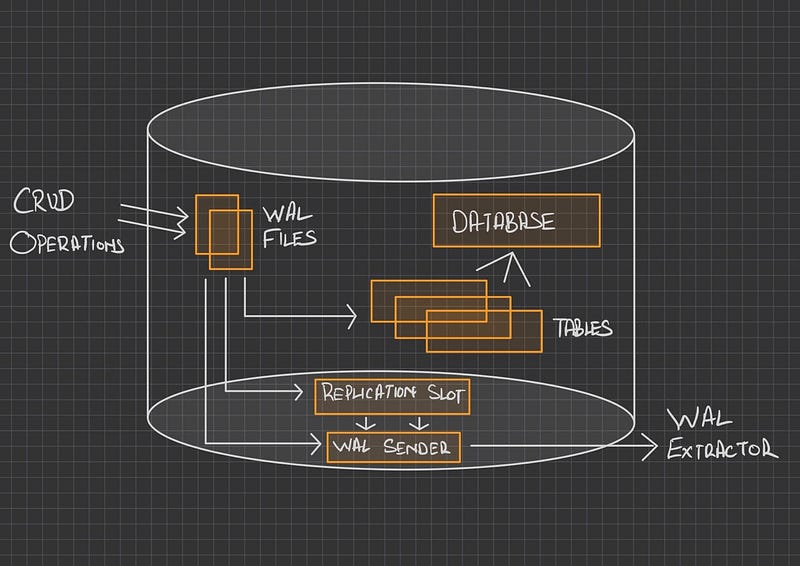
By far, log-based Change-Data-Capture is the most practiced approach in the industry to deal with real-time data updates. Particularly in Postgres, before any change is committed to the database, the raw event is first written to a file called a Write-Ahead-Log (WAL) file, which is persisted on disk for a set limit of size.
We use this file to extract database changes; be it a creation of a new record, updating a record, or deleting one.
Pros:
- Updates to the log files can be captured in real-time and streamed.
- Has no adverse performance implications as data is being read from files and no query is being made on the database.
Cons:
- Comparatively difficult to implement and maintain.
- Applying denormalization could become a tricky procedure and requires additional infrastructure to achieve that (more on that in the elasticsearch post linked above).
Implementation
We’ll be implementing the logs-based approach in Python and stream events to the stdout and shall further conclude with some existing implementations that could be used for a variety of use-cases.
Setting up Postgres
For streaming logs from Postgres in a readable JSON format, we would need to install a wal2json extension on our Postgres instance. Below I’m sharing my Postgres Dockerfile to have this set up for you in no time:
FROM postgres:11.4
LABEL maintainer="sahilmalhotra848@gmail.com"
COPY setup-primary.sh /docker-entrypoint-initdb.d/setup-primary.sh
WORKDIR /workspace
COPY wal2json-master.zip wal2json-master.zip
RUN apt-get update && \
apt-get install -y wget unzip make gcc postgresql-server-dev-11 && \
unzip wal2json-master.zip && \ cd wal2json-master && \ make && \
make install && \
apt-get remove -y unzip wget make gcc postgresql-server-dev-11 && \ cd .. && \
rm -rf ./*
ENTRYPOINT /docker-entrypoint.sh postgres
If you’re not familiar with docker, you can follow the steps from the wal2json repository to set it up manually.
Reading and Streaming logs using Python.
We’ll define the core functionality of streaming logs in a class, consisting of these methods:
1. Making connection to a Postgres instance for replication
def start_replication_server(self):
"""Setup/Connect to the replication slots at Postgres
"""
connect_string = 'host={0} port={1} dbname={2} user={3} password={4}'.format(
self.host, self.port, self.dbname, self.user, self.password)
self.conn = psycopg2.connect(
connect_string, connection_factory=psycopg2.extras.LogicalReplicationConnection)
self.cur = self.conn.cursor()
try:
self.cur.start_replication(
slot_name=self.replication_slot, decode=True)
except psycopg2.ProgrammingError:
self.cur.create_replication_slot(
self.replication_slot, output_plugin='wal2json')
self.cur.start_replication(
slot_name=self.replication_slot, decode=True)We’ll be using python’s psycopg2 library to make database connections. It is particularly important to mention the connection factory as logical replication here.
A replication slot is also created, which helps Postgres to checkpoint logs that are yet to be consumed; so in case of a connection failure, it can start from the point where it left before.
2. Listening to, and Consuming Logs
def start_streaming(self, stream_receiver):
"""Listen and consume streams
Args:
cur (object): Cursor object
conn (object): Connection object
stream_receiver (function): Function to execute received streams
"""
while True:
logging.info("Starting streaming, press Control-C to end...")
try:
self.cur.consume_stream(stream_receiver)
except KeyboardInterrupt:
self.cur.close()
self.conn.close()
logging.warning("The slot '{0}' still exists. Drop it with "
"SELECT pg_drop_replication_slot('{0}'); if no longer needed.".format(self.replication_slot))
logging.info("Transaction logs will accumulate in pg_wal "
"until the slot is dropped.")
return
except:
time.sleep(5)
try:
self.start_replication_server()
except Exception as e:
logging.error(e)A while loop would be running forever, till we press Ctrl+C and would be consuming logs from the Postgres server using the consume_stream method and send the records as a parameter to a function called stream_reciever.
3. Sending or Transforming Logs to Destination
The stream_reciever argument used above is a function where a stream record object would be passed as a parameter. You can transform or filter this on the fly and send it to a destination database or a stream-processing server.
def send_to_destination(msg):
logging.info("Stream msg: " + msg.payload)We will be making a call to the start_streaming function in this way:
object.start_streaming(send_to_destination)To have this up and running for you very quick, clone this repository and do a:
cp default.env .env docker-compose up -d
..on your terminal.
On another terminal, run this:
docker logs -f postgres-cdc-stream
..to monitor the stream of records.
Create brands table inside the postgres database:
CREATE TABLE brands (
id serial PRIMARY KEY,
name VARCHAR (50)
);Insert some records in the brands table:
INSERT INTO brands VALUES(1, 'Brand Name 1');
INSERT INTO brands VALUES(2, 'Brand Name 2');
UPDATE brands SET name = 'New Brand Name 1' WHERE id = 1;
UPDATE brands SET name = 'New Brand Name 2' WHERE id = 2;..and see them log onto your second terminal.
You can modify the send_to_destination function to either send these logs to another stream processing server or directly load them into a Data Warehouse.
Conclusion
In this short post, we learned to efficiently extract data from Postgres in real-time and be able to send it to any destination server. Such a solution can help you build real-time data pipelines for a variety of use cases, including the ones mentioned above.
Various implementations of the CDC pattern can be found online. If you plan to use it with Kafka, you may want to have a look at the Open Source Debezium’s Postgres Connector, which implements and extract data using the CDC way and transports the logs into Kafka where you can further do stream-processing or other sorts of transformations and load it into different kinds of databases or sinks, as per your requirement. Again, for that purpose, the above-mentioned Dockerfile would help set up the required extensions (wal2json) on Postgres.